Съдържание
- Какво представляват микроформатите и структурираните данни?
- Стандарти и формати за описване на структурираните данни
- Schema.org – стандартът за структурирани данни
- Open Graph протокол за споделяне в социалните мрежи
- Microdata
- FOAF и Dublin Core - извън стандартния SEO фокус
- Какъв синтаксис се използва за структурираните данни
- JSON-LD – препоръчителният избор
- Microdata – подходящ за специфични платформи
- RDFa / RDFa Lite – по-рядко в SEO практиката
- Кои типове структурирани данни са най-полезни за SEO
- Как да имплементирате структурирани данни в сайта
- Чести грешки при работа със структурирани данни
- Какво да запомните за структурираните данни, речниците и синтаксиса
- Често задавани въпроси (FAQ)
Микроформатите служат като помощни инструменти за представяне на съдържанието пред търсачките и AI ботовете. Като ключови инструменти в SEO, те позволяват на ботовете да разбират по-добре съдържанието на страницата, а част от него може да се визуализира и в снипета на сайта.
За SEO специалистите е важно да могат ясно да разграничават отделните типове и елементите, които могат да бъдат описани.
Какво представляват микроформатите и структурираните данни?
През последните години съдържанието в сайтовете не служи само на потребителите, но и на бранда, представяйки на търсещите и AI ботовете информация за бизнеса. За да могат Google и другите търсещи машини да разбират по-добре информацията, се използват така наречените “структурирани данни”. Част от по-ранните подходи към семантичното маркиране са и микроформатите. Двата вида често се бъркат, но всъщност имат съществена разлика.
-
Микроформатите са по-стар начин за предоставяне на структурирана информация. За тях са се използвали стандартни HTML шаблони от microformats.org, които представят информацията чрез класове и атрибути посредством CSS (например class="h-card", class="p-name"). С времето този модел губи популярност поради функционални ограничения и бива изместен от по-модерни решения.
-
Структурираните данни са стандартизиран начин да предоставим информация от дадена страница към ботовете. Най-често за целта се използва речника Schema.org, чрез който показваме на Google, Bing и другите търсачки дали на страницата ни има продукт, статия, полезна секция или информация за бизнеса.
Днес структурираните данни, описани чрез JSON-LD и библиотеката Schema.org, са най-широко разпространени. Те се поддържат и разбират от ботовете на търсачките и AI моделите, ключови са за по-богат снипет в резултатите (rich result) и са неизменна част от SEO оптимизацията.
Стандарти и формати за описване на структурираните данни
За да работите ефективно със структурирани данни, е важно да разграничавате кой речник за какво служи и къде има реална SEO стойност. Не всички семантични речници влияят на богатия снипет в резултатите на Google, но някои са ключови в различни аспекти.
Schema.org – стандартът за структурирани данни
Schema.org е съвместен проект на Google, Bing, Yahoo и други търсачки и към днешна дата е стандартният речник за описване на съдържанието в интернет. Той е в основата на повечето обогатени резултати, обобщителни и информационни елементи и подобрени снипети.
Schema.org съдържа типове като Organization, LocalBusiness, Product, Offer, Article, Event, FAQPage, VideoObject и много други, с които да се опише информацията. Може да се използва с три основни синтаксиса: JSON-LD, microdata и RDFa и е основата, върху която Google изгражда повечето богати резултати.
Пример: Organization с JSON-LD
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Netpeak Bulgaria",
"url": "https://netpeak.bg/",
"logo": "https://netpeak.bg/webflow/assets/64075eb044002b3ae03eb4f3/640b42ed90971b3341e8f7c0_Netpeak%20logo.svg",
"contactPoint": [{
"@type": "ContactPoint",
"telephone": "+359 875 41 96 36",
"contactType": "customer service",
"areaServed": "BG"
}]
}
</script>
Този тип маркиране помага на Google да асоциира сайта с конкретна организация, да изгради Knowledge Graph профил и да показва по-коректни резултати при брандови търсения.
Важно: използвайте стандартни формати за дати ISO-8601 и валути ISO 4217, за да избегнете валидационни грешки.
Подробна документация на Schema.org има на официалния сайт.
Open Graph протокол за споделяне в социалните мрежи
Open Graph е речник, създаден от Facebook, който контролира как страниците се визуализират при споделяне в социални мрежи. Той влияе върху заглавието, изображението и описанието при споделяне в платформите, но също така и върху визуалното представяне на линковете в Messenger, Instagram, LinkedIn, Viber, Slack и др.
Няколко задължителни тага, които препоръчваме:
-
og:title - име на обекта;
-
og:type - тип на обекта. Ако на страницата има повече от един обект, трябва да се избере главен и да се посочи неговия тип. В различните типове може да се посочат различни допълнителни свойства;
-
og:image - URL изображения;
-
og:url - каноничен URL, който ще се добавя във Facebook;
-
og:description - кратко описание;
-
og:locale - език и държава, посочва се език_държава. Стойност по подразбиране - en_US.
Също така, има редица незадължителни тагове, които могат да се използват в зависимост от съдържанието на страницата:
-
og:audio - линк към аудио файл, който се отнася към обекта на описание;
-
og:locale:alternate - алтернативни езици, на които е достъпно описанието на обекта;
-
og:site_name - име на сайта;
-
og:video - линк към видео, което се отнася към обекта на описание.
Пример:
<meta property="og:description" content="Как да използвате Schema.org и JSON-LD за по-видими резултати в Google.">
<meta property="og:image" content="https://www.example.com/images/og-image.png">
<meta property="og:url" content="https://netpeak.bg/blog/microformats-seo">
<meta property="og:type" content="article">
Open Graph не влияе на резултатите в Google, но влияе на CTR при споделяне и общото възприятие на бранда.
Google може в отделни случаи индиректно да използва og:image като резервно изображение, но това не е официален сигнал и не гарантира показване на обогатени резултати.
Microdata
Microdata е HTML синтаксис за използване на Schema.org директно в съдържанието.
При microdata семантиката се описва чрез специални HTML атрибути:
-
itemscope - описва всеки блок отделно, позволява да се опише информация на ниво същност;
-
Itemtype - показва типа същност;
-
itemprop - дава възможност да се посочат допълнителни свойства.
Пример за отбелязване на контакти:
<div itemscope itemtype="https://schema.org/LocalBusiness">
<h1><span itemprop="name">Името на компанията</span></h1>
<span itemprop="description">Описание</span>
<div itemprop="address" itemscope itemtype="https://schema.org/PostalAddress">
<span itemprop="streetAddress">Адрес на улицата</span>
<span itemprop="addressLocality">Град</span>,
<span itemprop="addressRegion">Държава</span>
</div>
Phone: <span itemprop="telephone">Телефонен номер</span>
<meta itemprop="openingHours" content="Mo-Fr 09:00-18:00">
</div>
Microdata форматът не е предпочитан от Google и е желателно да не се използва, а да се замени с JSON-LD.
FOAF и Dublin Core - извън стандартния SEO фокус
FOAF и Dublin Core са RDF речници със специфично приложение, които имат историческа роля в развитието на семантичния уеб, но днес се считат за остарели и нямат практическо значение за SEO оптимизацията за търсачки.
-
FOAF – (Friend of a Friend) речник, предназначен за описание на хора и връзките между тях. С помощта на този речник може да се посочи степента на близост на хората. Първоначално е използван основно в блогове и социални мрежи. FOAF не се използва за структурирани данни в Google и не влияе върху резултатите;
-
Dublin Core – описателен речник, създаден за нуждите на библиотеки, архиви и музейното дело. Той дава възможност максимално подробно да се опишат експонати и книги. Важно е да се отбележи, че Dublin Core не е SEO стандарт, а инструмент за каталогизация и управление на информационни ресурси.
Въпреки че FOAF и Dublin Core допринасят за концепцията на семантичния уеб, те нямат практическо приложение в съвременната SEO оптимизация и не се използват от Google за визуални подобрения в SERP. Функционалността, която тези речници предоставят като структурирано описание на обекти и техните характеристики, днес се реализира по стандартизиран, поддържан и SEO-релевантен начин чрез Schema.org и JSON-LD.
Какъв синтаксис се използва за структурираните данни
Речникът (Schema.org) е „какво“ описваме, а синтаксисът е „как го пишем“ в кода. Изборът на синтаксис влияе основно върху поддръжката и стабилността на маркирането, а не върху директното класиране. В практиката Google разпознава три основни синтаксиса.
JSON-LD – препоръчителният избор
JSON-LD е формат, който описва обектите в <script type="application/ld+json"> без да се „бърка“ в HTML структурата на страницата.
Основни предимства:
-
отделен е от HTML – лесен за поддръжка и генерация от CMS;
-
по-малко грешки при редакции на фронтенда;
-
Google изрично казва, че в повечето случаи препоръчва JSON-LD като най-лесен за имплементация формат.
Към днешна дата JSON-LD е стандартът за нови имплементации на структурирани данни.
Пример:
{
"@context": "https://schema.org",
"@type": "Product",
"name": "Калъф за телефон",
"offers": {
"@type": "Offer",
"price": "15.00",
"priceCurrency": "BGN"
}
}
</script>
Този код не се вижда от потребителя, но позволява на търсачките ясно да разберат какъв тип информация съдържа страницата.
Microdata – подходящ за специфични платформи
Microdata използва атрибутите itemscope, itemtype, itemprop и се добавя директно върху HTML елементи. Визуално са лесни за разбиране, но правят HTML кода на страницата по-тежък.
Пример:
<span itemprop="name">Калъф за телефон</span>
<span itemprop="price" content="15.00">15 лв</span>
<meta itemprop="priceCurrency" content="BGN">
</div>
При някои CMS платформи microdata се генерира автоматично, поради което все още се среща в сайтовете. Въпреки това e труднa за поддръжка и редактиране, поради което е препоръчително да се използва JSON-LD синтаксиса.
RDFa / RDFa Lite – по-рядко в SEO практиката
RDFa използва атрибути като typeof, property, vocab. Предлага по-голяма изразителност, но е по-сложен за имплементация и се използва по-рядко в масовите платформи и SEO практиката. Най-често се среща в академични среди и сложни структури.
Следният пример показва защо RDFa рядко се използва в SEO практиката - кодът е труден за четене и поддръжка.
property="description">January 2015 Visa</h1><a
property="url" href="https://acmebank.com/invoice.pdf">Invoice PDF</a>
<div property="broker" typeof="BankOrCreditUnion">
<b property="name">ACME Bank</b></div>
<span property="accountId">xxxx-xxxx-xxxx-1234</span>
<div property="customer" typeof="Person">
<b property="name">Jane Doe</b></div><time property="paymentDueDate">2015-01-30
</time><div property="minimumPaymentDue" typeof="PriceSpecification">
<span property="price">15.00</span><span property="priceCurrency">USD</span>
</div><div property="totalPaymentDue" typeof="PriceSpecification">
<span property="price">200.00</span><span property="priceCurrency">USD</span>
</div><meta property="billingPeriod" content="2014-12-21/P30D"
/>starts:2014-12-21 30 days<link property="paymentStatus" href="PaymentDue"
/></div>
Въпреки различните възможности, днес най-предпочитания синтаксис от маркетолози и агенти е JSON-LD. Той е лесен за поддръжка, автоматизация и управление, като все още няма реални недостатъци.
Кои типове структурирани данни са най-полезни за SEO
Като SEO специалисти е важно да знаем кои типове структурирани данни имат най-голямо влияние и да ги приоритизираме в своита стратегии.
Основни групи структурирани данни
Ще разгледаме следните групи и какви типове информация включват:
-
Маркиране на бранда и бизнеса – име, лого, контакти, адрес, описание, представяне.
-
Навигация и структура на сайта – хлебни трохички
-
Търговски и продуктови страници – име, цена, описание, оферта, отзиви.
-
Съдържание тип статия – заглавие, изображение, съдържание.
-
Локални сигнали – адрес, карта.
Това групиране позволява по-ясно планиране на типовете информация и по-лесната им техническа имплементация.
Най-често използвани типове структурирани данни
Следва да разгледаме конкретните типове schema markups, които най-често се използват на практика и имат пряко влияние върху видимостта на сайта. Ето най-важните от тях:
-
Organization - служи за маркиране на данните за бранда, включително име, лого, адрес и социални профили;
-
LocalBusiness - описва физическия обект, работно време и адрес;
-
Product - представя името, изображението и описанието на продукта;
-
Offer - съдържа цената на посочения продукт/услуга и я показва в снипета;
-
AggregateRating - отбелязва отзивите за продукта и ги визуализира в SERP;
-
BlogPosting - включва заглавие, дата на публикуване, текст или резюме; показва дата на публикуване в резултатите от търсене;
-
HowTo - семантично маркиране на стъпките за изпълнение; спомага за обогатени резултати.
Важно: Маркирайте само реалното съдържание от страниците, за да избегнете предупреждения в Google Search Console.
Класически пример за използване на структурирани данни е логото на фирмата. Чрез тях търсачките могат да разберат, че тази малка картинка горе в ляво представлява официалното лого на организацията, а не е просто декорация.
Натиснете с десния бутон на мишката върху логото и изберете “Копиране на адреса на изображението” или “Copy image address”:
За да бъде разпознато от търсачките, често се използва JSON-LD фрагмент, който описва организацията и URL на логото. Трябва да посочите:
-
Речника Schema.org.
-
Тип на данните, в нашия случай - “Organization”.
-
URL-адрес на страницата.
-
URL-адрес на логото.
Получаваме следния JSON-LD фрагмент за логото:
{
"@context": "https://schema.org",
"@type": "Organization",
"url": "https://www.example.com",
"logo": "https://www.example.com/images/logo.png"
}
</script>
Маркирането може да бъде проверено чрез Rich Results Test на Google или Schema Markup Validator, преди да бъде внедрено на сайта.
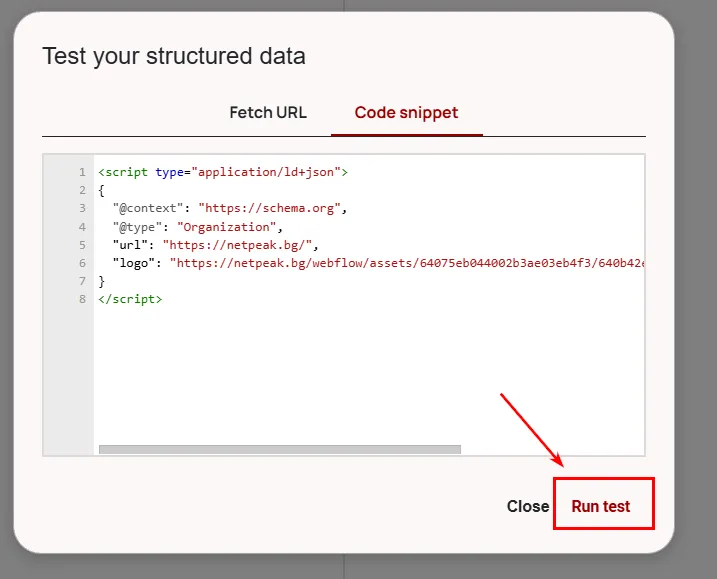
Резултат:
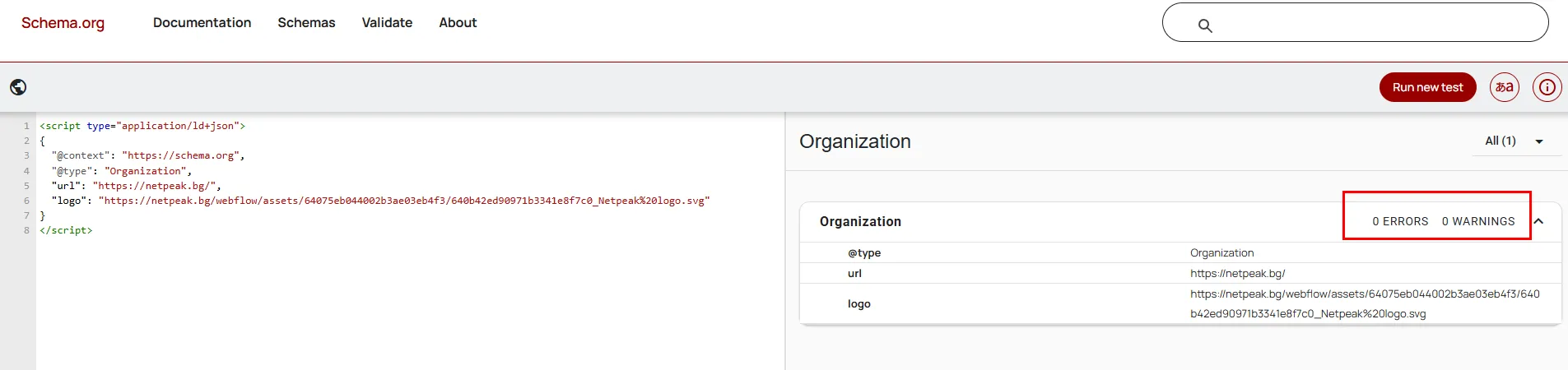
Ако всичко е коректно, JSON-LD маркирането може да се внедри в сайта.
Ако структурираните данни се генерират чрез JavaScript и с други инструменти като Google Tag Manager е препоръчително да се използва Server-Side Rendering, D, за да сте сигурни, че Google и Bing ще видят маркирането
Как да имплементирате структурирани данни в сайта
Без значение дали работите по големи или малки сайтове, хаотичното маркиране на елементите може да доведе до множество грешки. Затова е добре да планирате тази задача и да следвате стъпките:
-
Определете типовете страници
Отделете страниците спрямо съдържанието им - продуктови, статии, информационни, контаки и други.
-
Изберете вида на структурираните данни по типове страници
За всяка група страници опредлете подходящия тип структурирани данни. Например:
-
Продуктови страни - тип Product с информация за Offer
-
Блог статии - BlogPosting
-
Страница с контакти - ContactPage
-
Начална страница - Organization
-
Категории и вътрешни страници - BreadcrumbList
*Това е само пример и не е задължително да се спазва точно.
-
Синтаксис
Разпишете шаблони за всеки от типовете структурирани данни, които ще имплементирате. След това на база шаблона попълнете данните и направете проверка на готовия скрипт.
-
Имплементация
Спрямо шаблоните, оформете легенди за извличане на посочените данни - това ще улесни глобалната имплементация. Посочете къде трябва да се поставят скриптовете, като най-често това е преди </body> тага.
-
Внедряване и тестване
Имплементирайте структурираните данни на демо среда или на някои от страниците. Тествайте в инструментите резултата и ако всичко е наред ги внедрете във всички страници.
-
Мониторинг
В Google Search Console можете лесно да проследявате ефективността на различните типове структурирани данни. В случай на грешка, конзолата ще сигнализира и можете да отстраните проблема.
Важно: Всяка промяна по шаблони, теми, CMS плъгини или миграции трябва да се придружава от повторен тест на структурирани данни с Rich Results Test, Schema Markup Validator и GSC, за да се гарантира, че маркирането остава валидно и функционално.
Чести грешки при работа със структурирани данни
Ето основните проблеми, които се срещат най-често:
-
използване на няколко синтаксиса и описване на едни и същи елементи с тях;
-
неправилно маркиране – отбелязване на съдържание, което не отговаря на реалността (пример: използване на Product в информационна страница, без да има реално продаван продукт);
-
маркиране на невидимо или подвеждащо съдържание – текст, който не се вижда от ботовете и/или потребителите, но е отбелязан като Review или FAQ;
-
прекалено агресивно, автоматично „наливане“ на структурирани данни без смисъл – например добавяне на FAQ типа на всеки раздел, без да съдържа секция с ЧЗВ;
-
липса на актуализация – оставяне на остаряла структура след промяна на навигация, URL адреси или дизайн.
След всяка имплементация е добре да се направи системен преглед, за да не се стигне до масови предупреждения и грешки в Google Search Console.
Какво да запомните за структурираните данни, речниците и синтаксиса
През 2026 г. структурирани данни вече не са допълнение – те са част от базовия SEO чеклист. Ключовото е да мислите за тях като инструмент, който прави сайта ви по-видим и по-разбираем за търсачките и AI асистентите.
Няколко основни точки, които да вземете под внимание:
-
мислете за Schema.org + JSON-LD като стандартна основа;
-
използвайте Rich Results Test, Schema Markup Validator и Google Search Console като постоянни инструменти за контрол;
-
планирайте внедряването по тип страници и бизнес цели;
-
добре структурираното съдържание помага не само за органичните резултати при търсене, но и за AI асистентите, които все по-често са първата връзка между потребител и сайт.
С правилно планиране и внимание към детайла сайтът ви не просто ще се вижда от търсачките, а ще стане естествена част от техните отговори.
Снипетът ще бъде по-привлекалетелен, ще имате по-богати данни в SERP-а и агентите ще разбират по-лесно съдържанието ви.
Често задавани въпроси
▶ 1. Влияят ли структурираните данни пряко върху класирането в Google?
Не влияят пряко, само индиректно. Структурираните данни помагат на Google да разбере сайта по-добре, да го показва с разширени визуални елементи и да повишава CTR. Така влиянието върху SEO идва чрез по-добро визуално представяне и по-точно съотношение между заявка и съдържание.
▶ 2. Влияят ли структурните данни върху AI Overviews и асистентите като ChatGPT или Gemini?
Да. AI системите използват структурирани данни, за да извличат факти, часове, имена, цени, описания, характеристики на продукти, инструкции (HowTo), FAQ блокове и други. Добре структурираният сайт има по-голям шанс да бъде част от директния AI отговор.
▶ 3. Какво да правя, ако Google Search Console показва „Страницата е допустима, но не се показва като разширен резултат“?
Нищо, това е нормално. Google не гарантира показване на разширени резултати. Алгоритъмът преценява дали визуалното разширение е подходящо за конкретната заявка. Важно е единствено кодът да е валиден и данните да са коректни.

 2
2
 0
0
 2
2