Вътрешни дублирани страници - как да се справим с тях?
Представете си следната ситуация: в сайта ви има страници с различни URL адреси, които показват едно и също или почти едно и също съдържание. На пръв поглед това не изглежда като сериозен проблем – информацията е налична, потребителят я вижда, всичко работи.
За търсачките обаче ситуацията е различна.
Когато едно и също съдържание е достъпно през няколко URL-а, търсачките трябва сами да решат коя версия е основната, коя да индексират и коя да игнорират. Това често води до технически и SEO проблеми, които могат да повлияят негативно на видимостта на сайта.
В тази статия ще разгледаме:
-
какво представляват вътрешните дублирани страници;
-
какви видове дубликати съществуват;
-
защо са проблем за SEO;
-
как да ги откриете;
-
и как да ги отстраните по правилния начин.
Дублирани страници – какво означава това?

Дублирани страници са страници в рамките на един сайт, чието съдържание напълно или частично съвпада, но са достъпни през различни URL адреси.
Важно е да се отбележи, че в повечето случаи дубликатите не са създадени умишлено. Те често възникват като страничен ефект от начина, по който е изграден сайтът – CMS настройки, филтри, параметри, странициране или промени в структурата.
Duplicate, Similar и Thin content – каква е разликата?
1. Duplicate content (дублирано съдържание)
Това е съдържание, което е еднакво или почти еднакво и се показва на повече от един URL.
Проблемът тук е, че търсачките не знаят коя версия да считат за „оригинална“.
2. Similar / near-duplicate content (подобно съдържание)
При подобното съдържание страниците не са 1:1 копия, но се припокриват значително. Това може да се случи при шаблонни страници, леко пренаписани текстове или различни версии на една и съща информация.
Търсачките често възприемат тези страници като конкуриращи се помежду си.
3. Thin content (бедно съдържание)
Това са страници с много малка стойност за потребителя – малко текст, автоматично генерирани елементи или празни листинги.
Често thin страниците съществуват паралелно с дубликати и усилват негативния ефект.
Как възникват дублирани страници?
1. Автоматично генериране от CMS
Много системи за управление на съдържанието създават повече от един URL за една и съща страница.
Пример:
И двете страници показват едно и също съдържание, но за търсачката това са два различни ресурса.
2. Грешки при категоризацията
Когато един и същ продукт е част от няколко категории, той често става достъпен през различни URL-и.
В резултат се създават няколко версии на една и съща продуктова страница, които започват да се конкурират помежду си.
3. Промени в структурата без правилна миграция
При реорганизация на сайта често се създават нови URL-и, но старите не се премахват или пренасочват.
Така съдържанието се дублира, без това да е очевидно за администратора на сайта.

Пълни дубликати
Пълните дубликати са страници с напълно идентично съдържание, но различни адреси.
Най-чести примери и защо са проблем:
Наклонени черти (/, //, ///)
За сървъра това може да е една и съща страница, но за търсачката – два различни URL-а.
HTTP и HTTPS
Ако и двете версии са достъпни, сайтът съществува в два варианта, което води до дублиране на цялото съдържание.
www и без www
Без ясно зададена основна версия търсачките не знаят коя да индексират.
index / home / default варианти
Това са класически пълни дубликати, които често остават незабелязани.
Главни и малки букви
Търсачките третират тези URL-и като различни, въпреки че съдържанието е едно и също.
Параметри, UTM тагове и проследяване
Параметрите са полезни за анализ, но без контрол създават множество дублирани версии.
Частични дубликати
Частичните дубликати са по-трудни за откриване, защото съдържанието не е напълно еднакво, но се припокрива значително.
Това обърква търсачките, тъй като не е ясно коя страница има по-голяма стойност и за каква заявка трябва да се показва.
Категории и продуктови страници
Често срещан сценарий е продуктовото описание да присъства както в категорията, така и в самата продуктова страница.
Проблемът тук е, че категорията започва да „конкурира“ продукта за едни и същи ключови думи. В резултат нито една от страниците не се представя оптимално.
Добра практика: категориите трябва да имат общо, обобщаващо описание, а продуктите – уникално, детайлно описание.
Филтри, сортиране и странициране
При използване на филтри и сортиране се генерират множество страници със сходно съдържание, където се променя само редът или малка част от елементите. За търсачките тези страници често нямат самостоятелна стойност и водят до разхищение на crawl budget.
При страницирането (pagination) – страници 2, 3 и т.н. – ситуацията е специфична. Критична грешка е да се постави каноничен таг от втора или трета страница към първата. Това може да накара търсачките да спрат да обхождат съдържанието на следващите страници и така продуктите или статиите в тях да останат неиндексирани.
Добра практика: всяка страница от страницирането трябва да има автореферентен каноничен таг (т.е. страница 2 да сочи към страница 2).
Това позволява на Google да обходи целия списък с продукти, без да счита страниците за вредни дубликати на началната категория.
Print / Download версии
Тези страници показват едно и също съдържание, но са предназначени за различна употреба. Ако не бъдат контролирани, те се третират като дубликати.
Какви са последствията от дублираните страници?
1. Проблеми с индексирането
Търсачките обхождат повече страници, отколкото е необходимо, и често пропускат важни URL-и.
2. Грешна страница в резултатите
Алгоритъмът може да избере версия на URL, която не е оптимизирана за потребителя или за конкретната заявка.
3. Размиване на линк сигналите
Линковете се разпределят между няколко версии на една и съща страница, вместо да подсилват една основна.
Начини на откриване на дублирани страници
След като вече изяснихме какво представляват дублираните страници, какви видове съществуват и какви проблеми могат да създадат, следва логичният въпрос – как да ги открием навреме.
На практика най-добрият резултат се постига чрез комбинация от технически анализ и проверка на вече индексираните страници. По-долу разглеждаме най-ефективните подходи.
С помощта на специални инструменти
Един от най-надеждните и широко използвани методи за откриване на дублирани страници е чрез технически crawl на сайта със специализиран SEO софтуер като Netpeak Spider.
Инструментът позволява да се открият както пълни, така и частични дубликати, още преди те да се превърнат в реален SEO проблем.
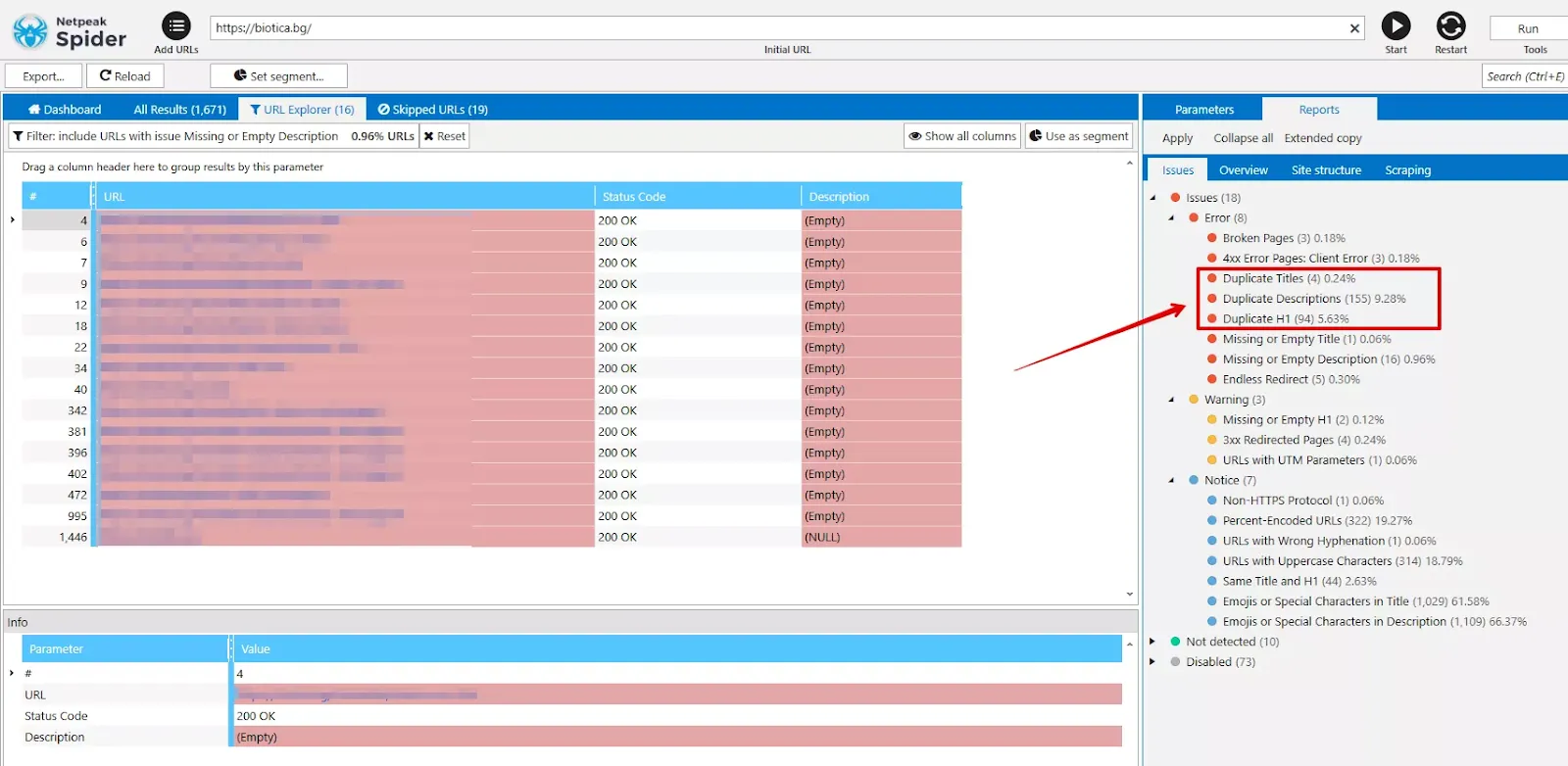
С помощта на Netpeak Spider могат да бъдат анализирани:
-
напълно дублирани страници (идентично съдържание);
-
частично дублирано съдържание в основния <body> блок;
-
повтарящи се метаданни като:
-
Title,
-
H1,
-
Meta Description.
-
Този тип анализ е особено ценен, защото показва реалната структура на сайта, включително URL-и, които може още да не са индексирани от Google, но вече съществуват и консумират crawl budget.
Откриване на дублирани страници чрез търсещи оператори в Google
Освен чрез специализиран софтуер, дубликатите могат да бъдат открити и чрез търсещи оператори, които показват как Google вече възприема сайта.
Този подход е полезен за бърза проверка и за валидиране дали проблемите вече са видими в индекса.
Оператор site:
В полето за търсене въведете:
site:examplesite.bg
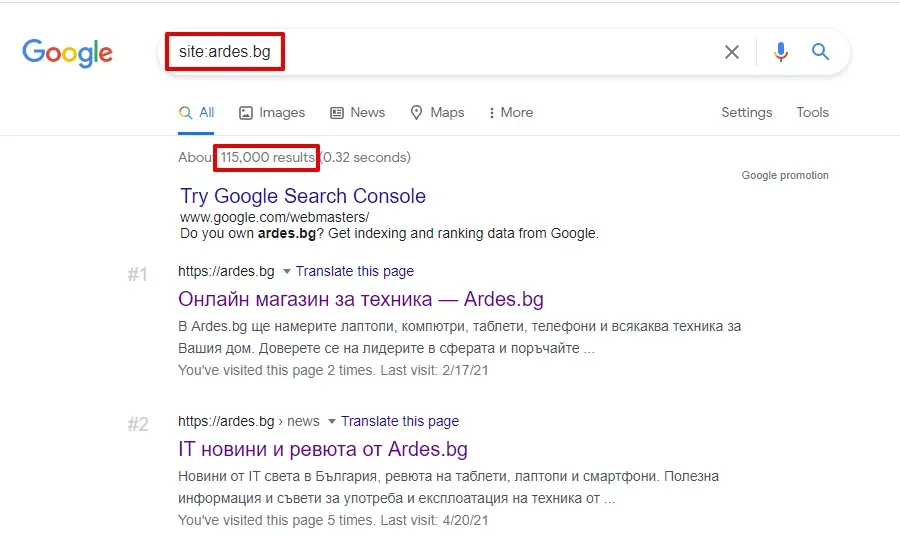
Резултатът показва приблизителния брой страници от сайта, които Google е индексирал.
Ако този брой е значително по-голям от:
-
реалния брой важни страници в сайта, или
-
броя URL-и в XML sitemap-а
това често е индикатор за наличие на дублирани страници, параметризирани URL-и, филтри или страници с ниска стойност.
При преглед на резултатите често могат да се забележат и визуални индикации за дублиране – сходни заглавия, еднакви описания или повтарящи се URL структури.
Оператор „текст“ + site:
Този метод позволява да се провери дали един и същ текст се среща на повече от една страница.
Примерна заявка:
"Фрагмент от текст от страницата" site:example.bg
Ако се появят няколко резултата, това означава, че съдържанието е дублирано или частично припокриващо се.
Методът е особено полезен при:
-
дублирани продуктови описания;
-
припокриване между категории и продукти;
-
повторения в шаблонни текстове.
Оператор site: + intitle:
Чрез оператора intitle: може да се провери дали няколко страници използват един и същ Title.
Пример:
site:examplesite.bg intitle:примерен title
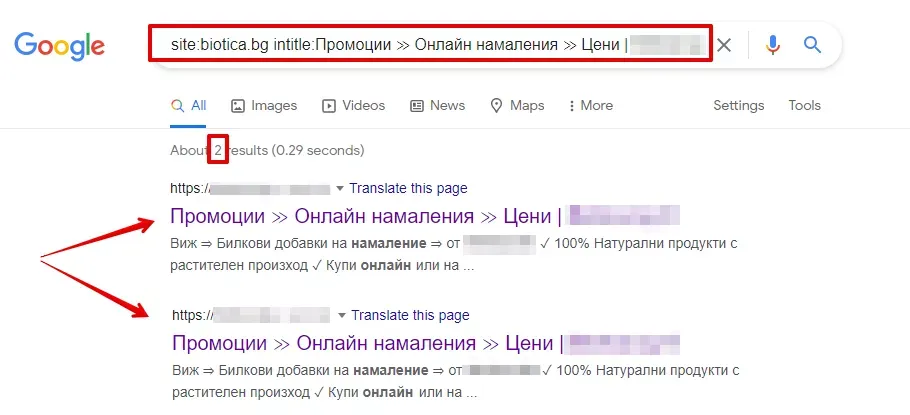
Повтарящите се Title тагове често са признак за:
-
дублирано съдържание;
-
неправилно генерирани шаблони;
-
липса на уникализация при категорийни и филтърни страници.
Това затруднява търсачките при избора на правилната страница за показване в резултатите.
Оператор site: + inurl:
Този оператор е изключително полезен за откриване на дубликати, създадени от:
-
филтри;
-
сортиране;
-
вътрешно търсене;
-
URL параметри.
Пример:
site:examplesite.bg inurl:filter
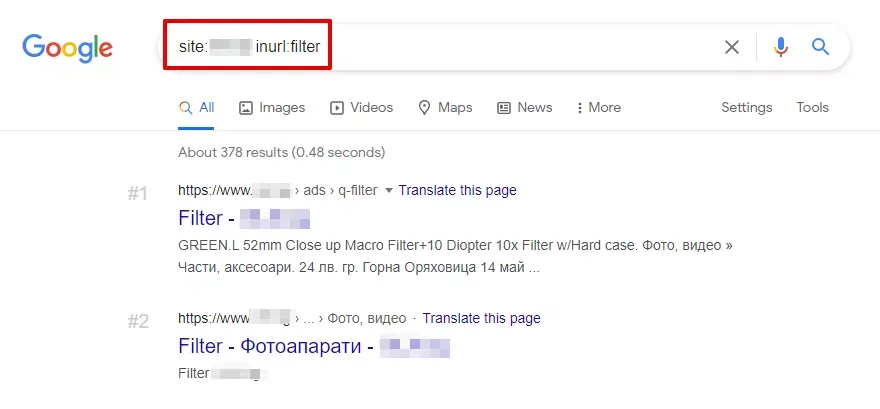
Така лесно могат да се открият страници, които генерират сходно съдържание и често нямат самостоятелна SEO стойност.
Важно уточнение
Търсещите оператори показват само онези дублирани страници, които вече са индексирани от Google.
Това означава, че част от проблемите може все още да не са видими чрез този метод.
Затова най-добрият подход остава:
-
технически анализ с Netpeak Spider, за да се открият всички потенциални дубликати;
-
допълваща проверка с търсещи оператори, за да се види как Google интерпретира сайта в момента.
Как да се справим с дубликатите?
Вече разбрахме какво представляват дублираните страници, какви видове съществуват и какви проблеми могат да създадат. Следва логичният въпрос – как да ги премахнем или контролираме, така че да не вредят на SEO представянето на сайта?
Важно е да се отбележи, че няма универсално решение. Подходът зависи от това дали дадена страница:
-
трябва напълно да изчезне;
-
трябва да остане достъпна за потребителя;
-
или просто не трябва да бъде индексирана от търсачките.
По-долу разглеждаме най-често използваните и най-надеждни методи.
301 редирект – основният метод за пълни дубликати
301 редиректът е най-сигурният и предпочитан метод за премахване на пълни дубликати, когато дадена страница няма причина да съществува самостоятелно.
При 301 редирект търсачките разбират, че дадената страница е преместена за постоянно на нов адрес. По този начин:
-
дублираният URL спира да се използва;
-
SEO сигналите (линк тежест, авторитет) се прехвърлят към правилната страница;
-
търсачките спират да обхождат излишните URL-и.
Кога е подходящ 301 редирект?
301 редиректът е правилният избор при дубликати, причинени от:
-
URL адреси с малки и големи букви;
-
различна йерархия на URL-а за едно и също съдържание;
-
избор на основна версия на сайта (www или без www);
-
проблеми с наклонени черти в URL адресите.
Пример
Дублирани URL-и:
Всички те се пренасочват към правилния и предпочитан адрес:
Така за търсачките остава само една ясна версия на страницата.
robots.txt – контрол на обхождането, не на индексирането
Файлът robots.txt се използва, за да се дадат указания на търсещите роботи кои страници да не бъдат обхождани.
Това става чрез директивата Disallow, например:
User-agent: *
Disallow: /page
Този подход е полезен, когато сайтът генерира:
-
безкрайни филтри;
-
вътрешни търсения;
-
технически URL-и без SEO стойност.
Важно уточнение
robots.txt не е надежден метод за премахване на дубликати от индекса.
Причината е, че:
-
ако страницата вече е била индексирана;
-
или има вътрешни/външни линкове към нея,
тя все още може да се показва в резултатите от търсенето, дори да е забранена за обхождане.
Затова robots.txt трябва да се използва като инструмент за оптимизация на crawl budget, а не като основен метод за деиндексиране.
Meta robots тагове: noindex, nofollow и noindex, follow
Друг ефективен начин за контрол на дублирани страници е използването на meta robots тагове, които се поставят в <head> секцията на HTML кода.
1. noindex, nofollow
<meta name="robots" content="noindex, nofollow">
Този таг казва на търсачките:
-
да не индексират страницата;
-
да не следват линковете, поставени в нея.
Използва се, когато страницата няма стойност нито сама по себе си, нито като източник на вътрешни линкове.
2. noindex, follow
<meta name="robots" content="noindex, follow">
Този вариант:
-
забранява индексирането на страницата;
-
но позволява на търсачките да следват линковете от нея.
Това е предпочитан избор при дублирани страници, които:
-
трябва да съществуват за потребителя;
-
но не трябва да се конкурират с основната версия в резултатите от търсенето.
Как работи на практика?
При първото обхождане търсачката:
-
не индексира страницата;
-
но може да използва вътрешните ѝ линкове.
При последващи обхождания страницата постепенно се премахва от индекса. В дългосрочен план разликата между noindex, follow и noindex, nofollow е минимална, но първият вариант е по-безопасен за вътрешното линкване.
Ключово правило: за да работи noindex, страницата не трябва да бъде блокирана в robots.txt, иначе търсачката може изобщо да не види този таг.
Атрибут rel="canonical" – когато страницата трябва да остане
Атрибутът rel="canonical" е един от най-мощните инструменти в SEO. Той се използва, когато дадена страница трябва да бъде достъпна за потребителите, но не искате търсачките да я приемат за самостоятелен ресурс. Чрез него указваме коя е предпочитаната (основна) версия на съдържанието, която Google трябва да индексира и към която да се насочва целият авторитет (link equity).
Автореферентен каноничен таг (Self-referential canonical)
Критично важна практика е всяка уникална страница в сайта да притежава каноничен таг, който сочи към самата нея. Това е най-добрата превантивна мярка срещу неочаквано генерирани дубликати (например от външни линкове с UTM параметри, ID-та на сесии или проследяващи кодове). По този начин вие изрично посочвате на търсачката кой е оригиналният URL адрес и предотвратявате размиването на неговата сила.
Canonical е особено подходящ за:
-
страници с филтри и сортиране;
-
URL-и с GET параметри и UTM маркери;
-
print версии на страници;
-
сходно съдържание в различни езикови версии или домейни.
Пример с категория и филтри
Онлайн магазин има категория „Лаптопи“, която съдържа филтри по марка, цвят, размер на екрана и други характеристики. Всеки филтър генерира нов URL, но съдържанието е сходно.
В този случай е правилно всички филтрирани версии да имат канонична връзка към основната категория:
Дублирани URL-и:
Canonical в HTML кода:
<link rel="canonical" href="https://site.bg/example" />
По този начин търсачките разбират коя версия е основната и не третират останалите като самостоятелни страници.
Обобщение
Най-важното при работа с дублирани страници е изборът на правилния метод според конкретния случай:
-
301 редирект – когато дубликатът е напълно излишен;
-
rel="canonical" – когато страницата трябва да съществува, но не и да се индексира;
-
noindex – когато страницата е полезна за потребителя, но не и за търсачките;
-
robots.txt – за контрол на обхождането и ограничаване на crawl budget.
Комбинацията от тези методи позволява дублираните страници да бъдат контролирани, а не просто „замаскирани“, което води до по-стабилно и предвидимо SEO представяне.
Заключение
Вътрешните дублирани страници са често срещан проблем, който възниква най-често в резултат на автоматично генериране на URL-и, грешки в настройките или промени в структурата на сайта. Те могат да доведат до затруднения при индексирането, размиване на релевантността в резултатите от търсенето и загуба на линк сигнали между няколко версии на една и съща страница.
За да бъдат открити навреме, е препоръчително да се използва комбинация от технически анализ със специализирани инструменти като Netpeak Spider и проверка на индексираните страници чрез търсещи оператори.
Отстраняването на дубликатите зависи от конкретния случай и най-често включва:
-
301 редирект за напълно излишни страници;
-
rel="canonical" за сходни или параметризирани URL-и;
-
noindex за страници, които трябва да съществуват, но не и да се индексират;
-
контрол на обхождането чрез robots.txt.
Редовният анализ за дублирани страници помага да се поддържа чиста и ясна структура на сайта и да се избегнат бъдещи SEO проблеми.
И не забравяйте - THERE CAN BE ONLY ONE!

 62
62
 9
9
 13
13
Препоръчани нови статии
Микроформати и структурирани данни: какво трябва да знае всеки SEO специалист
Как да помогнем на търсещите машини да структурират и разберат информацията в сайта.
Netpeak Bulgaria получи статут на Microsoft Advertising Elite Partner за 2026
Netpeak Bulgaria е Google Premier Partner 2026 и сред водещите performance компании в страната