Какво представляват log файловете и как да ги използваме за технически одит
В съвременната дигитална среда ИТ екосистемите станаха твърде комплексни за ръчен надзор. Анализът на log файлове е процесът, който превръща първичните, компютърно генерирани записи в actionable intelligence (използваема информация), поддържаща критични бизнес и технически цели.
Докато инструменти като Google Search Console предлагат обобщени данни, log файловете остават най-надеждният начин да разберете как търсачките и потребителите взаимодействат със сайта ви в реално време.

Какво е log файл?
Log файлът е автоматично генериран запис (дневник), който съхранява хронологична информация за събития в дадена система, приложение или мрежа. Казано просто: това е дигитална следа на „какво се е случило“, „кога се е случило“ и често „кой/какво го е инициирало“.
Log файловете са ключови за мониторинг на:
-
производителност и стабилност;
-
откриване на грешки;
-
сигурност;
-
исторически анализ на поведението на системата.
Какво е log файл в SEO?
В контекста на SEO, log файловете обикновено означават уеб сървърни access log файлове, които записват всяка заявка към сайта: както от реални потребители, така и от ботове на търсачки и други автоматизирани системи.
Точно затова те са „златна мина“ за техническо SEO: показват реалната картина на обхождането и достъпа до ресурси.
Каква информация съдържат SEO log файловете?
Най-често ще срещнете:
-
IP адреси – помагат да разграничите източника на заявките и да идентифицирате ботове/краулери. Важно уточнение: Според GDPR, IP адресите се считат за лични данни. Когато обработвате log файлове, трябва да се уверите, че спазвате политиките за поверителност и съхранявате данните в защитена среда, особено ако ги споделяте с външни инструменти или трети страни.“
-
User-Agent – показва кой прави заявката (браузър, устройство, бот) и е ключов за анализ на crawler поведение.
-
Заявен URL – кои страници/изображения/CSS/JS ресурси са достъпвани, включително опити към несъществуващи адреси.
-
Timestamp (дата/час) – позволява анализ на тенденции и „ритъм“ на обхождане.
-
HTTP status code – как сървърът е отговорил (200, 301, 404, 500 и т.н.).
-
Referrer – откъде идва трафикът (ако е налично), полезно за частични изводи за навигация и линк структура.
Важно уточнение: log файловете често се пазят ограничено време (седмици до месеци), в зависимост от настройките на хостинга и обема трафик. При по-натоварени сайтове периодът може да е по-кратък.
Какво е log file analysis?
Log file анализът е процесът на достъп, изтегляне, преглед и интерпретация на сървърните log файлове с цел да се открият:
-
проблеми с crawling и индексиране;
-
технически грешки (404/5xx, неправилни редиректи);
-
загуба/разхищение на crawl budget;
-
„скрити“ проблеми, които не се виждат ясно в други източници.
Защо log file анализът е важен?
Най-голямата му стойност е, че работите с first-party данни — директно от сървъра. Това означава, че виждате нефилтрирана, пълна картина за всички заявки, от всички търсачки и ботове.
Ето основните ползи:
-
Пълна видимост върху crawling: кои URL-и се обхождат най-често и кои остават пренебрегнати.
-
Оптимизация на crawl budget: откривате URL-и без стойност, които „харчат“ ресурси (параметри, дубли, безкрайни филтри, празни страници).
-
Откриване на технически проблеми: 404, 410, 5xx, циклични/верижни редиректи, блокирани ресурси.
-
Идентифициране на orphan pages: страници без вътрешни линкове, до които ботът трудно достига по „нормален“ път.
-
Проверка на достъпността на важни страници: дали най-важните секции реално се обхождат и с каква честота.
-
Ранно предупреждение при аномалии: резки спадове/скокове в crawling активността често сигнализират за проблем (или значима промяна).
Процесът на анализ и техники
Ефективният анализ преминава през етапи на събиране на данни, индексиране, мониторинг и докладване. Използват се различни техники:
-
Разпознаване на патерни: Идентифициране на трендове в обхождането.
-
Откриване на аномалии: Засичане на необичайно поведение (например внезапен скок на 5xx грешки).
-
Верификация на ботовете: Тъй като User-Agent може да бъде фалшифициран (bot spoofing), задължително се прави Reverse DNS lookup, за да се потвърди, че заявката е от истински бот на търсачка.
Модерни инструменти за анализ (Scaling)
За управление на големи обеми от данни днес се използват специализирани платформи:
-
ELK Stack (Elasticsearch, Logstash, Kibana): Популярна екосистема с отворен код за индексиране и визуализация на логове.
-
Splunk: Мощен корпоративен инструмент (със Splunk екипите получават разширени възможности за търсене и мониторинг в реално време).
-
Cloud-Native решения: Интегрирани услуги като Sumo Logic или Tencent Cloud Log Service за облачен мониторинг.
Достъп и подготовка на log файла
Как да свалите log файл от cPanel (примерен процес)
Много хостинг среди използват cPanel, който позволява лесно изтегляне на raw access logs.
Типичните стъпки са:
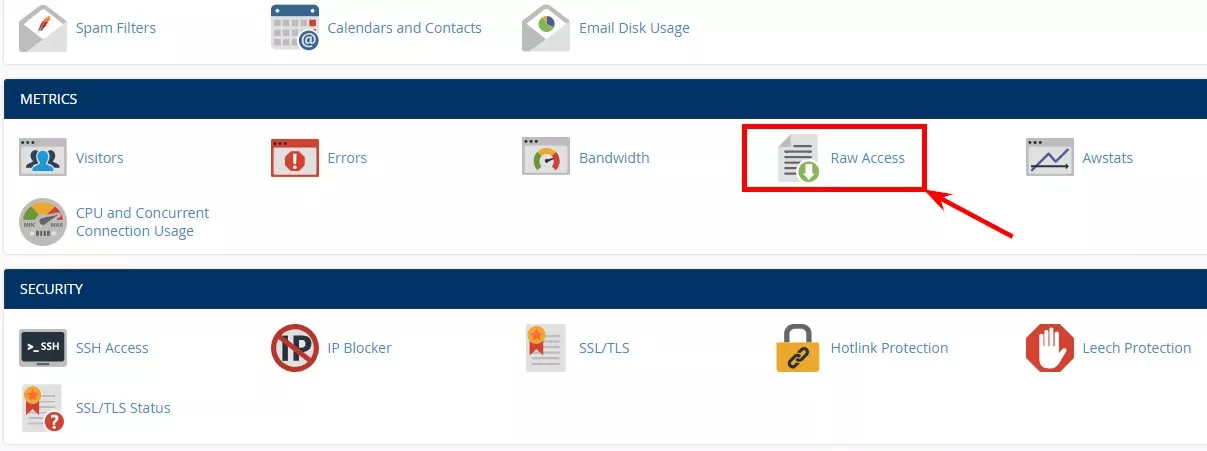
-
Намирате секция/бутон Raw Access:
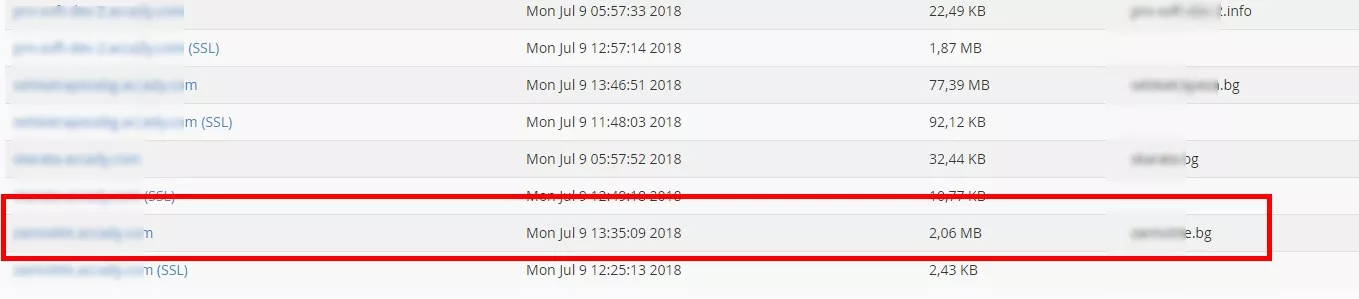
2. Избирате домейна/сайта:
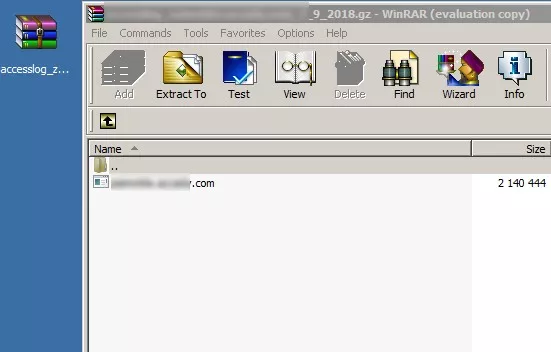
3. Сваляте архив (често .gz).
4. Разархивирате съдържанието.
5. При нужда преименувате/променяте файла с разширение .log
6. Подготвяте файла за анализ (филтриране, сортиране, групиране)
Формат на log файла (накратко, но практично)
Един от най-често срещаните формати е Apache Combined Log Format. Примерен шаблон:
"%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-agent}i\""
И примерен ред с реални данни би изглеждал по подобен начин:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
Където:
127.0.0.1 (%h) - IP адресът, който е генерирал заявката към сървъра.
- (%l) - logname (От identd, ако е налично). В случая тирето означава, че информацията не е налична.
frank (%u) - Userid на човека, извършващ заявката. Определя се чрез HTTP автентикация и оторизация.
[10/Oct/2000:13:55:36 -0700] (%t) - Дата и час, когато заявката е получена:
[day/month/year:hour:minute:second zone]
day = 2*digit
month = 3*letter
year = 4*digit
hour = 2*digit
minute = 2*digit
second = 2*digit
zone = (`+' | `-') 4*digit
"GET /apache_pb.gif HTTP/1.0" (\"%r\") - Тип на заявката, ползвания HTTP протокол и заявеният ресурс. От тук се взема много полезна информация, която LogAnalyzer обобщава.
200 (%>s) - Статус код или отговор на сървъра
2326 (%b) - Големина на отговора, който е върнат към клиента.
"http://www.example.com/start.html" (\"%{Referer}i\") - Referer HTTP request header
"Mozilla/4.08 [en] (Win98; I ;Nav)" (\"%{User-agent}i\") - User-agent, с който най-общо се дефинира browser, операционна система и тип на устройство.
Combined log на Apache сървърите е всъщност форматът по подразбиране за инструмента. Съществуват възможности за обработка и на други такива, но това става след предварителна заявка.
Ключовите елементи, които най-често ще използвате в SEO анализа, са:
-
Request (GET/POST + URL)
-
Status code (200/3xx/4xx/5xx)
-
User-Agent (бот/браузър)
-
Timestamp (кога се случва)
-
Referrer (ако е наличен)
Как да тълкувате данните: какво да гледате първо?
1. Статус кодове и грешки (4xx/5xx)
-
404/410: търсачката или потребителите търсят несъществуващи URL-и
Обичайни причини: счупени вътрешни линкове, стари URL-и, миграции без редирект план. -
5xx: сървърни проблеми, които пречат на crawling и могат да доведат до спадове във видимостта.
-
3xx (301/302): полезни при миграции, но ако са прекалено много или са „на вериги“, често разхищават ресурси.
Практичен сигнал: ако виждате необичайно висок процент 3xx или чести повторения на едни и същи редиректи, това обикновено е знак за вътрешен проблем в структурата или настройките.
2. Анализ на ботовете (User-Agent)
Един от най-ценните аспекти е да разграничите:
-
трафик от реални потребители;
-
трафик от търсачки (и кои точно);
-
други автоматизирани обхождания.
Тук се търсят отговори на въпроси като:
-
Колко често се обхожда сайтът?
-
Кои секции са приоритет?
-
Има ли важни страници, които се обхождат рядко или почти никога?
Експертен съвет: не се доверявайте сляпо само на User-Agent.
Тъй като той може лесно да бъде фалшифициран (т.нар. bot spoofing), за прецизен анализ е необходимо да се извърши DNS верификация (Reverse DNS lookup). Това потвърждава, че заявката реално идва от сървърите на Google или Bing, а не от зловреден скрипт, маскиран като бот на търсачка.
3. Crawl budget waste (разхищение)
Най-честите „виновници“:
-
параметризирани URL-и без стойност;
-
дублиращи страници;
-
безкрайни филтри;
-
вътрешни търсения и нискокачествени листинги;
-
ресурси/страници, които не трябва да се обхождат толкова често.
Целта е проста: повече crawling внимание към важните URL-и, по-малко към шум.
4. Orphan pages (страници без вътрешни връзки)
Log файловете могат да „подскажат“ за страници, които се появяват рядко, случайно или само чрез директни заявки, но нямат нормална навигационна достъпност. Това често е знак за:
-
липсващо вътрешно налинкване;
-
страници, които са „скрити“ от структурата;
-
неправилна информационна архитектура.
Чести заблуди при log file анализа
„Само големите сайтове имат нужда от log анализ“
Размерът не е единствен фактор. Дори малък сайт може да има:
-
неправилни редиректи,
-
масови 404,
-
параметри,
-
грешно приоритизирани секции, които търсачките обхождат непропорционално.
„Гледаме log файловете, само когато има проблем“
Това е като да гледате мониторинг едва след срив. Регулярният преглед помага да:
-
хванете проблемите рано,
-
имате база за сравнение „как изглежда нормалното“,
-
реагирате преди да има SEO щета.
„Други отчети елиминират нуждата от server logs“
Агрегираните данни са полезни, но log файловете остават „сървърната истина“: те показват всяка заявка, а не извадка или обобщение. Най-силният подход е да ползвате log данните като фундамент за технически изводи и действия.
Изводи
Анализът на сървърните log файлове е фундаментът на професионалната SEO диагностика и системната стабилност. Той премахва предположенията и предоставя чисти факти, което позволява на организациите да поддържат оптимално представяне пред търсачките и да намалят значително MTTR (Mean Time to Resolution) – средното време за откриване и отстраняване на критични технически проблеми.
Лог анализът предоставя реална и нефилтрирана картина за:
-
crawling поведението на търсачките в реално време;
-
техническите грешки, които остават скрити в агрегираните отчети;
-
разхищението на crawl budget и как да го оптимизирате;
-
достъпността и приоритета на най-важните за бизнеса URL адреси.
Най-важното: стойността на този процес не се крие в избора на конкретен продукт, а в правилното разчитане на данните и превръщането им в actionable intelligence – конкретни и стратегически действия, които гарантират дългосрочния успех на сайта.

 5
5
 0
0
 4
4